Smart Manufacturing
CAPRI Platform & the PySpark Connector: a bridge between FIWARE and Apache PySpark

Challenge & Context
European process industries stand on the brink of a great transformation to become circular and climate-neutral by 2050. They face energy and environmental efficiency issues due to shortages in raw materials supply, energy prices, and anti-pollution policies, which represent important constraints that must be dealt with, forcing them to adapt and adjust their manufacturing processes, regardless of their complexity.
Digitalization enables faster development of new solutions and speeds up engineering. It also allows for more intelligent operations and facilitates cross-sectoral collaboration by tracking data and sharing information in an effective and secure manner.
The European co-funded CAPRI (Cognitive Automation Platform for European PRocess Industry digital transformation) project brings cognitive solutions to the process industry by developing and testing an innovative Cognitive Automation Platform (CAP). It has been validated in three different use cases — namely within the asphalt, steel and pharmaceutical industries, leveraging the combination of sensors, information technologies, and new AI algorithms called “Cognitive Solutions”. It provides cognitive tools that enable more flexibility in operation, improve performances across different indicators (KPIs) and ensure state-of-the-art quality control of products and intermediate flows.
Three main technical objectives have been pursued:
- digital transformation and automation of the process industry through technologies like data collection, storage, and knowledge extraction, to provide detailed insights into process control and resource availability;
- improved performance and flexibility in the process industry via digitalization to dramatically accelerate changes in resource management and in the design and the deployment of disruptive new business models;
- next-generation process industry plans for autonomous operation of plants based on embedded cognitive reasoning, while relying on high-level supervisory control, and providing support for optimised human-driven decision-making.
The Cognitive Automation Platform aims to support the entire data flow, from data collection to data utilisation, including:
- Facilitating data acquisition from heterogeneous sources (IIoT and custom systems).
- Allowing the historicization of data generated in the IoT or industrial field on ad-hoc storage.
- Enabling the usage of data supporting applications.
- Providing a business analytics suite based on machine learning and cognitive algorithms.
- Ensuring the persistence of the output derived from the analytics performed (both in terms of models and predictions).
- Managing business analytics based on batch data and streaming data.
- Allowing the management of edü ge or wide scenarios.
- Integrating security modules for user management.
- Upholding data sovereignty principles.
From this scenario, the PySpark Connector was born, with the aim of enriching the FIWARE solution for Python, a commonly used programming language. This need arises from the necessity to exchange data bidirectionally between the previously mentioned Cognitive Solutions and the Cognitive Automation Platform.
Solution
The CAP is based on a layered reference architecture, as depicted in Figure 1, which can be summarized into several functional macro-components:
- Smart Field contains the Industrial IoT (IIoT) physical layer, composed of machines, sensors, devices, actuators and adapters.
- External Systems defines enterprise systems (ERPs, PLMs, customized, etc.) for supporting processes and adapters.
- Smart Data Management and Integration contains the Data Management and the Data Integration sub-modules. Regarding Data Management, it defines information and semantic models for data representation of Data in Motion (DiM), Data at Rest (DaR) and Situational Data. Furthermore, this component is responsible for data storage, data processing, and the integration of data analytics and cognitive services.
- Smart Data Spaces and Applications represents the data application services for representing and consuming historical, streaming, and processed data.
- Security defines components for the authorization and authentication of users and systems. It also integrates modules for data protection and privacy.
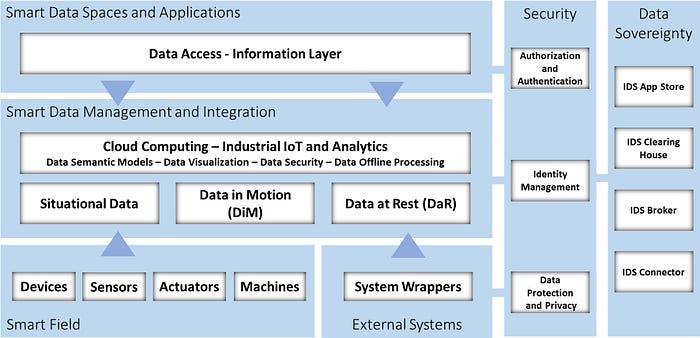
Components in every layer can be combined following a Lego -bricks-like approach, adhering to the exposed data schema, making the architecture flexible and adaptable to the specific needs of the various application domains in the process industry. Simultaneously, the modularity enables the adoption of a microservice design for the application, resulting in smaller software code that can be organised as docker containers. This allows them to run on smaller processing elements and with restricted resources.
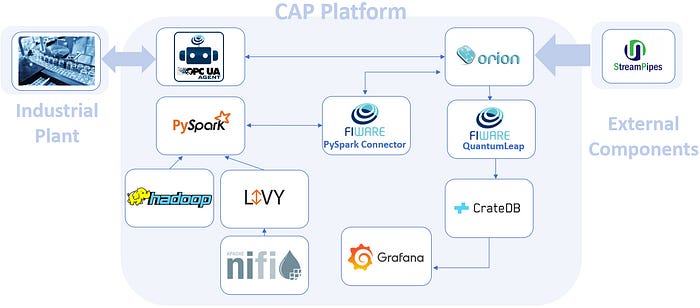
In the pharmaceutical use case, the CAP has been developed using Open-Source technologies from the FIWARE catalogue and is based on Apache technologies, as shown in Figure 2.
The industrial plant allows the CAP to operate in streaming mode (Data in Motion), but through Apache Nifi it is possible to feed the CAP in batch mode (Data at Rest). With Apache Livy, the execution of PySpark commands becomes feasible.
Once the data from the industrial plant is collected and published in the Orion Context Broker, the bidirectional exchange of data from Orion to the cognitive solutions integrated in Apache PySpark is facilitated by the FIWARE PySpark Connector, a component acting as a bridge between FIWARE and Apache components.
PySpark Connector
The FIWARE PySpark Connector is an incubated FIWARE Generic Enabler composed of a receiver and a replier, allowing bidirectional communication between the FIWARE Context Broker and Apache PySpark. The component operates through low-level socket communication, implementing a message-passing interface between the two counterparts. This interface is equipped with a parser function, enabling the creation of NGSIv2 or NGSI-LD entities for use in a custom PySpark algorithm. Once data has been pre-processed within the PySpark environment, the component also provides a write-back interface (via REST API) to the Context Broker.
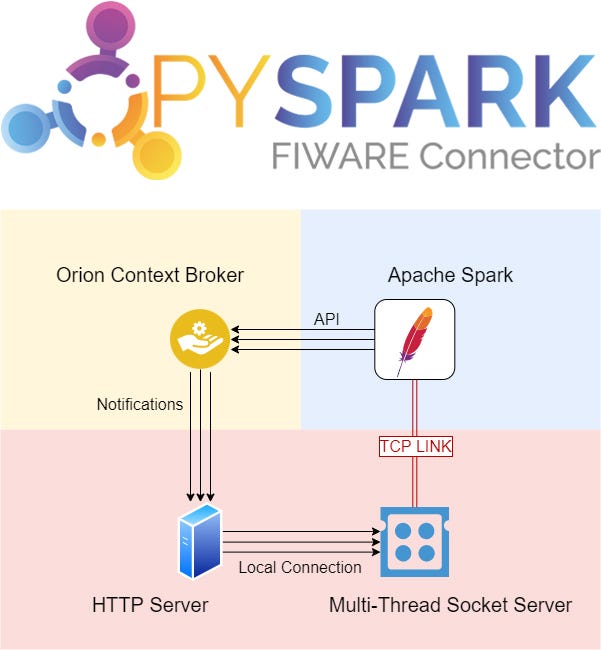
As Python is currently one of the most widely used programming languages for data analysis, boasting an extensive array of scientific libraries for data processing and visualisation, the FIWARE PySpark Connector serves as a natural extension to the AI domain, further expanding the FIWARE environment. The FIWARE Orion Context Broker is positioned at the heart of the infrastructure, facilitating the exchange of context information in a powerful manner, particularly in this case through a new communication channel with Apache PySpark.
How it works
The mechanism behind the PySpark connector is quite straightforward: it sets up a basic HTTP server to receive notifications from the FIWARE Context Broker and then transfers this data into Apache PySpark using the SocketTextStream function, which generates an input TCP source for building Resilient Distributed Datasets (RDDs), the streaming data unit of Apache PySpark. Figure 4 illustrates the detailed process of connector setup, followed by data reception, management, processing, and sinking.

The first phase involves setting up the FIWARE PySpark connector, assuming that the PySpark session has already started. The Prime function of the FIWARE PySpark connector is executed. Once the connector’s multi-thread socket server (MTSS) starts, it remains in a listening phase. When the PySpark streaming context is initialised the PySpark’s SocketTextStream function creates a TCP input using any available local IP and port, connecting to MTSS. Subsequently, the MTSS preserves PySpark’s TCP socket, and the end streaming context and RDD channel are returned.
The second phase is for data reception. Assuming that the connector’s HTTP Server is subscribed to the FIWARE Context Broker for a particular entity, when an attribute of the subscribed entity changes, FIWARE Context Broker sends a notification to the connector’s HTTP Server. During this phase, the HTTP server organizes the incoming HTTP packet into a string message and opens a random socket, sending the incoming message to the central socket of MTSS. This socket receives the message and opens a new thread to manage this connection, passing the message to PySpark’s SocketTextStream. Subsequently, PySpark maps the incoming message to a worker machine where the string message is parsed into an NGSIEvent object. The NGSIEvent is now available as RDD.
The third phase is dedicated to data processing. In this phase, the Spark driver maps the RDD containing NGSIEvent objects to a worker. After this, a map function utilises a custom processing function, taking an RDD as input and returning the custom function’s output as “mapped” RDD. The result is then returned as an RDD.
The fourth phase oversees data write-back. The Spark driver executes the forEachRDD function, which then passes each RDD to the forEachPartition function, thereby mapping the final result to a worker. The forEachRDD function is invoked on RDD synchronisation, while forEachPartition allows the setup of connector parameters only once, after which it iterates on incoming RDDs. The forEachPartition requires a callback function that uses an iterator as an argument. In the end, the Spark Driver sinks the data flux, mapping an output function to the worker, and the connector sends a POST/PATCH/PUT request to the Orion Context Broker, displaying Orion’s response.
In summary, the FIWARE PySpark connector runs a multi-thread socket server that enables the listening phase, facilitated by its subscription to the FIWARE Context Broker. It receives data and forwards it to Apache PySpark via a SocketTextStream. Once Apache PySpark completes the processing phase and returns the result to the FIWARE PySpark Connector, it can structure the incoming information in NGSIv2/LD format and invoke the Orion Context Broker API to update the context information.
Benefits & Impact
Although the PySpark Connector may be seen as a single component facilitating bi-directional interaction between Apache PySpark and the FIWARE Context Broker, it also ensures real-time monitoring of the Cognitive Solutions integrated into the Cognitive Automation Platform.
In a broader perspective, the PySpark Connector enhances the robustness of the tablet production process through dedicated control loops integrated into cognitive algorithms that rely on data-driven and hybrid parametrized process models. Furthermore, it maintains consistent product quality by continually checking and monitoring results obtained during the various stages of the production process.
Finally, the deployment of the PySpark connector within the Cognitive Automation Platform has a significant impact on reducing labour efforts, as it now supports or replace offline product testing (analytics) with automated processes in the Cognitive Automation Platform.
Added value through FIWARE
The Cognitive Automation Platform, with its FIWARE incubated PySpark Connector, is a modular and Open-Source framework capable of deploying cognitive functions from the edge to the cloud.
It is built on FIWARE’s best-in-class European Open Source Community and complemented with APACHE’s worldwide OSS market leadership.
Data Interoperability is achieved by adopting the NGSIv2/LD Data Model as a common data format in the industrial sector, ensuring compatibility with several technological components and facilitating easy data exchange within the CAP platform.
This interoperability, made possible through the use of FIWARE Open Source components, represents an elementa element of CAPRI’s replicability in the process industry. It enables the management of cognitive tasks, as well as data collection, storage, processing, and presentation directly from the plant.
Next steps
The next steps in evolving the FIWARE PySpark Connector represent a significant expansion of its capabilities, transforming it from a Single Input, Single Output (SISO) component into a Multi-Input, Multi-Output (MIMO) connector. This change will enhance its scalability and versatility across a wide range of use cases.
The connector will be upgraded to support multiple PySpark jobs simultaneously. This means it can handle multiple data streams and processing tasks concurrently, increasing its efficiency.
Additionally, the connector will incorporate support for the NGSI-LD temporal API, enabling it to work with time-series data and be compliant with components such as FIWARE Mintaka. This capability is crucial for applications that require historical data analysis and trend identification.
Finally, it will be enabled for integration with popular messaging brokers like Apache Kafka and/or ActiveMQ. This will allow seamless data exchange with a variety of systems, making it an integral part of larger, distributed data processing architectures.
Security will also be a top priority, with the integration of components like FIWARE Keyrock and/or FIWARE Wilma for secure connections. This will ensure that data exchanges are protected, and only authorised entities can access the connector.
To conclude, the evolution of the FIWARE PySpark Connector includes further stress testing and extensive integration tests across several production systems. These activities are intended to demonstrate the connector’s efficiency in real-world IoT applications, leading to a substantial enhancement of its capabilities.
This, in turn, will contribute significantly to the end of the incubation and its full inclusion in the FIWARE Catalogue.
References
- This work has been supported by the CAPRI Project, which has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement №870062.
- More information on the FIWARE PySpark Connector
- More information about the Cognitive Automation Platform on GitHub
Author & Contributors
Mattia Giuseppe Marzano
Software Development Specialist @ Engineering
Gabriele De Luca
Technical Manager @ Engineering
Marta Calderaro
Project Manager @ Engineering
Angelo Marguglio
Head of Digital Industry R&I Unit @ Engineering
— — — — —
Disclaimer
In accordance with our guidelines on the use of quotes and impact stories in advertising, please note the following points: Impact stories appearing on the FIWARE Foundation website or other digital or printed materials and channels were submitted via text, audio or video. They are individual experiences that reflect real life and business experiences of those who have used our technology and/or services in different ways. The information contained in this impact story is not medical, diagnostic or therapeutic advice and does not constitute advice, treatment or application recommendations or guidance for the individual case. FIWARE Foundation does not assume any responsibility for up-to-datedness, correctness and completeness of the information provided. Liability claims against the author, which refer to material or non-material damages, which were caused by the use or non-use of the provided information or by the use of incorrect and incomplete information, are generally excluded, unless there is no evidence of intentional or negligence of the author. All offers are subject to change and non-binding. The author expressly reserves the right to change, supplement or delete parts of the pages or the entire offer without separate announcement or to discontinue the publication temporarily or permanently. Some FIWARE Impact Stories may be shortened.
